Glassdoor Analysis:
Data Jobs In USA
💼 About the Project
The job market in data-related fields is rapidly evolving, with high demand for skilled professionals in various industries. This project aims to scrape job listings for Data Analyst, Data Scientist, and Data Engineer positions from Glassdoor in five major US cities: Seattle, Austin, Los Angeles, New York, and San Francisco. The collected data will be used for further analysis, visualization, and predicting trends in the job market.
Tools used
- python 3.8
- Sellenium
Project Repository
🚩 Problem Statment
The available public job datasets are not reliable for understanding the current job market as they become outdated within a short period of time.
To gain a more accurate understanding of the current job market trends, we aim to scrape the job board website Glassdoor, which provides up-to-date job postings. By analyzing this data, we can explore the current job market conditions and make more informed decisions about our future career paths.
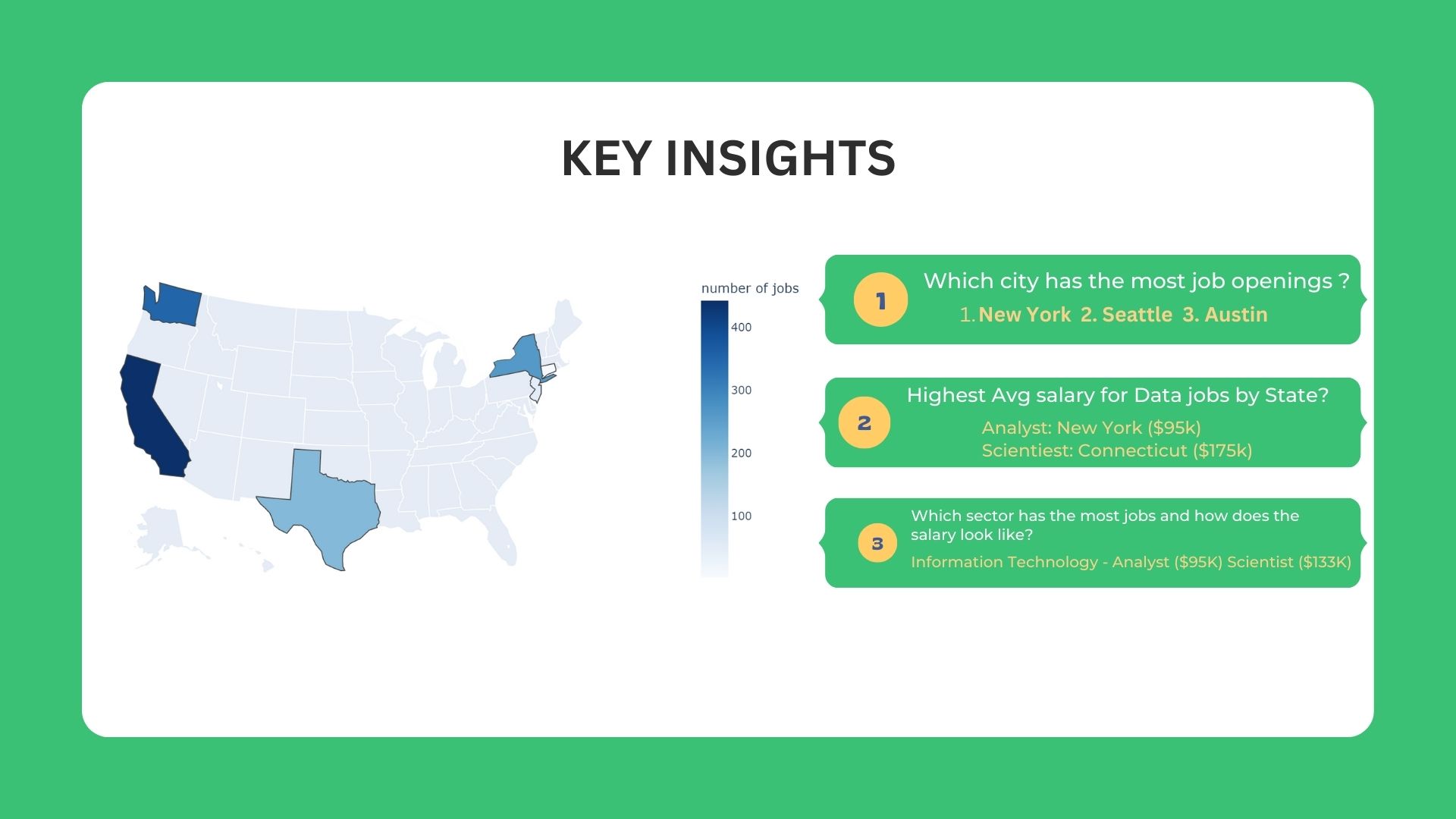
🧐 Research Questions
The project aims to answer the listed questions (Job titles selected in the interest of the author)
📈 Workflow
- Data Scraping
- Data Cleaning
- Data Analysis
ℹ️ Data Scraping
Using browser automation package Seleninum to scrape the data from the glassdoor website. Below is example data table.

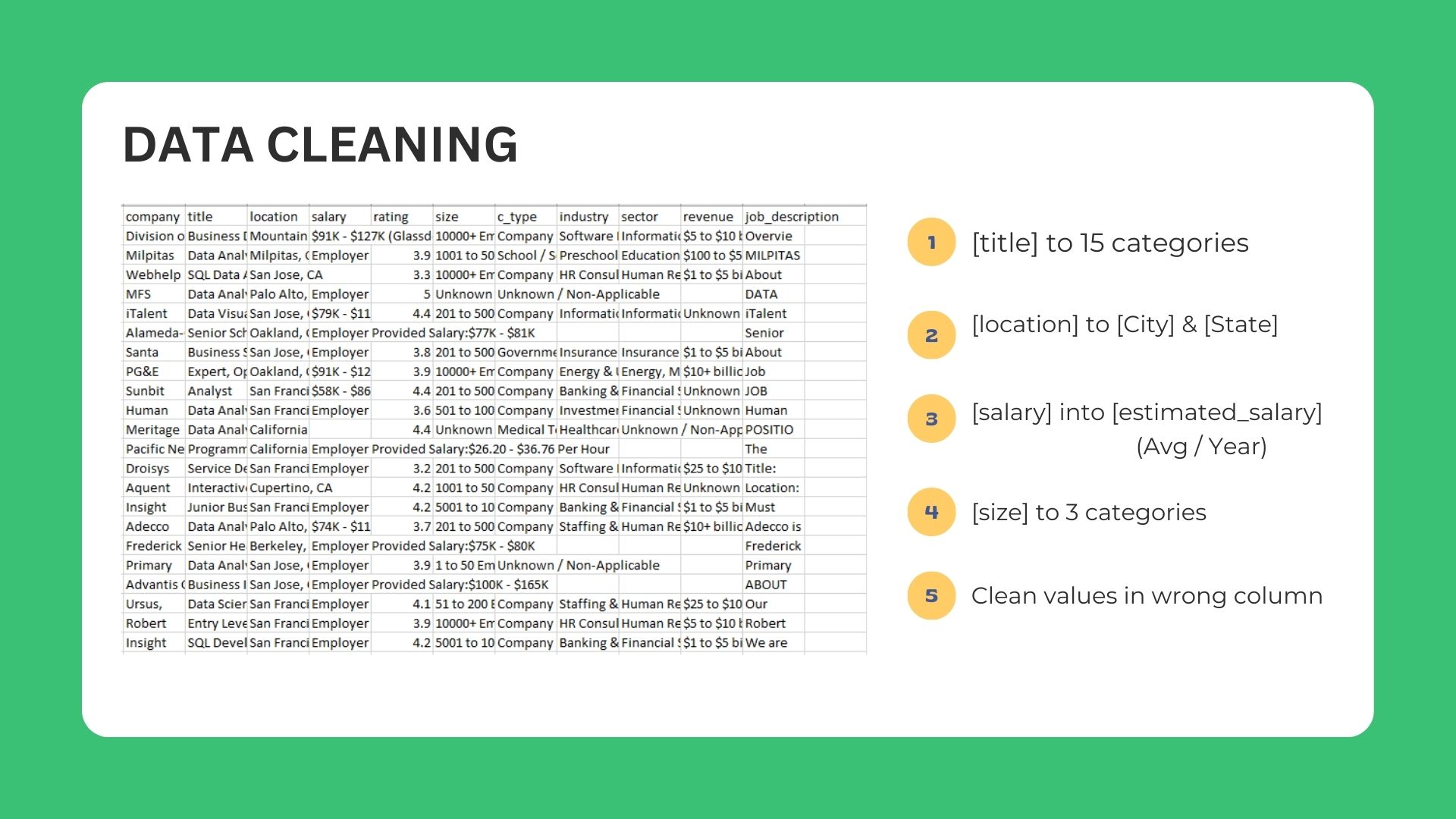
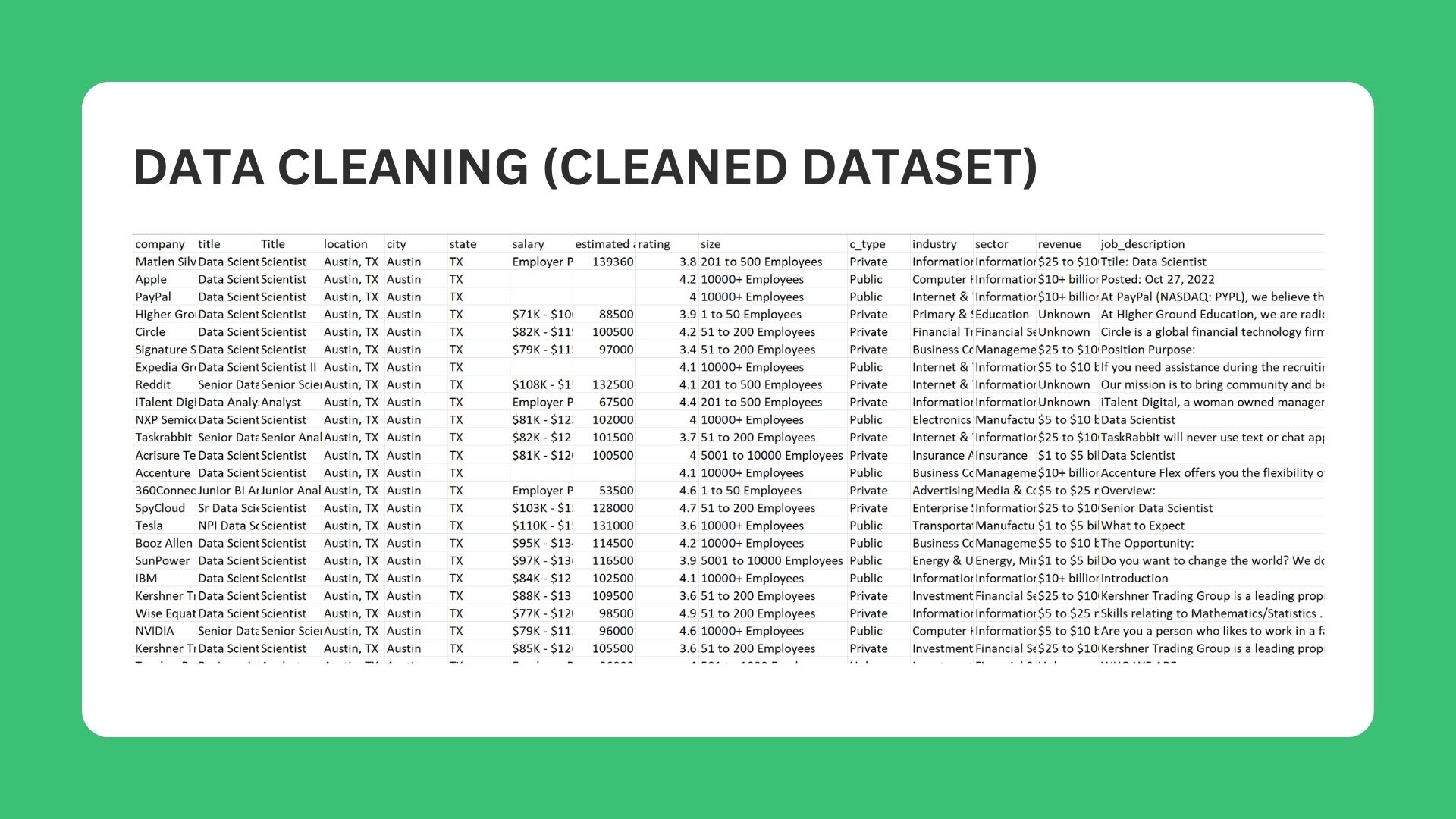
🧼 Data Cleaing
Data cleaning process aims to clean any null values or miss scraped columns using python
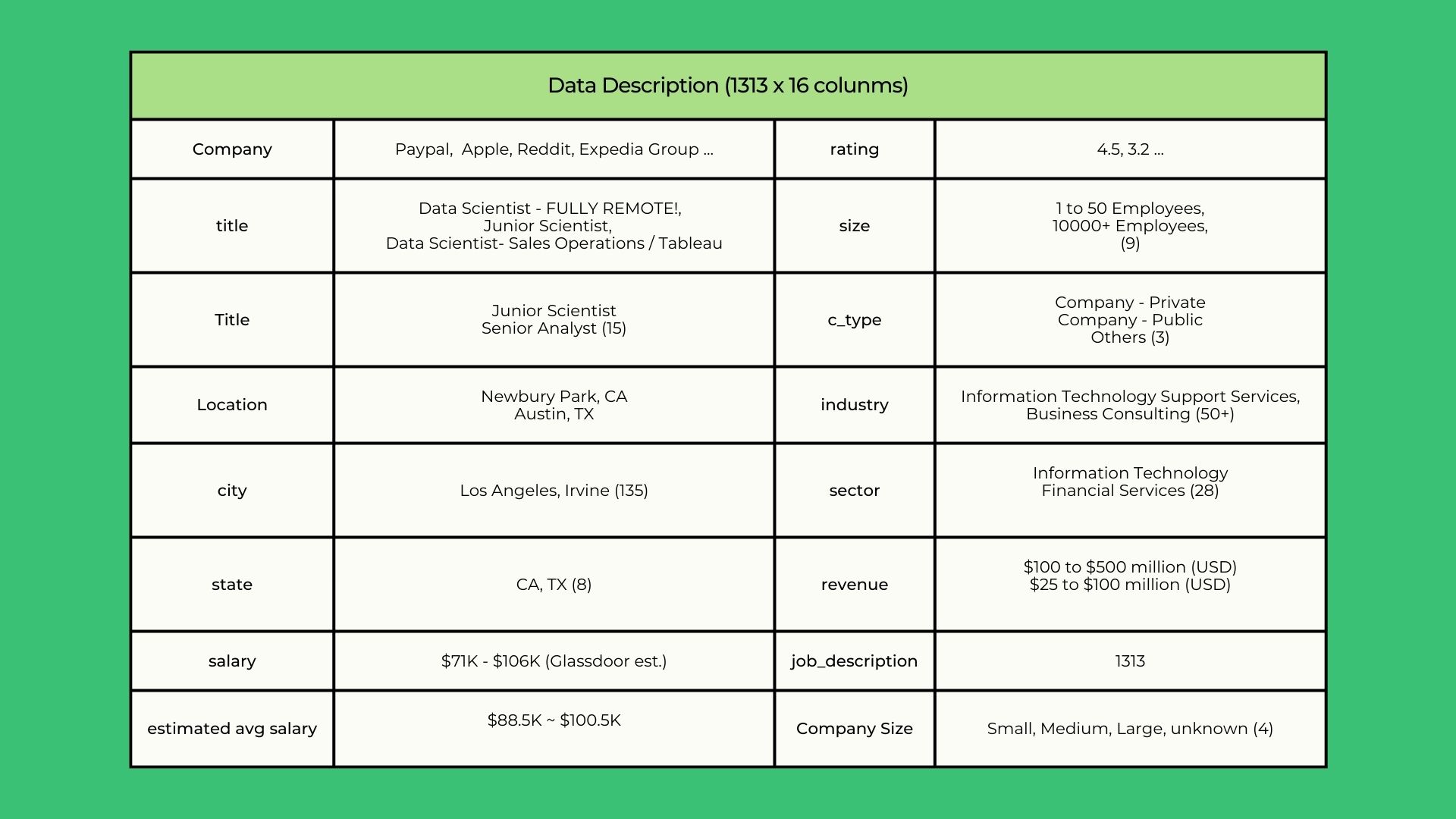
📊 Data Analysis
Data cleaning process aims to clean any null values or miss scraped columns using python
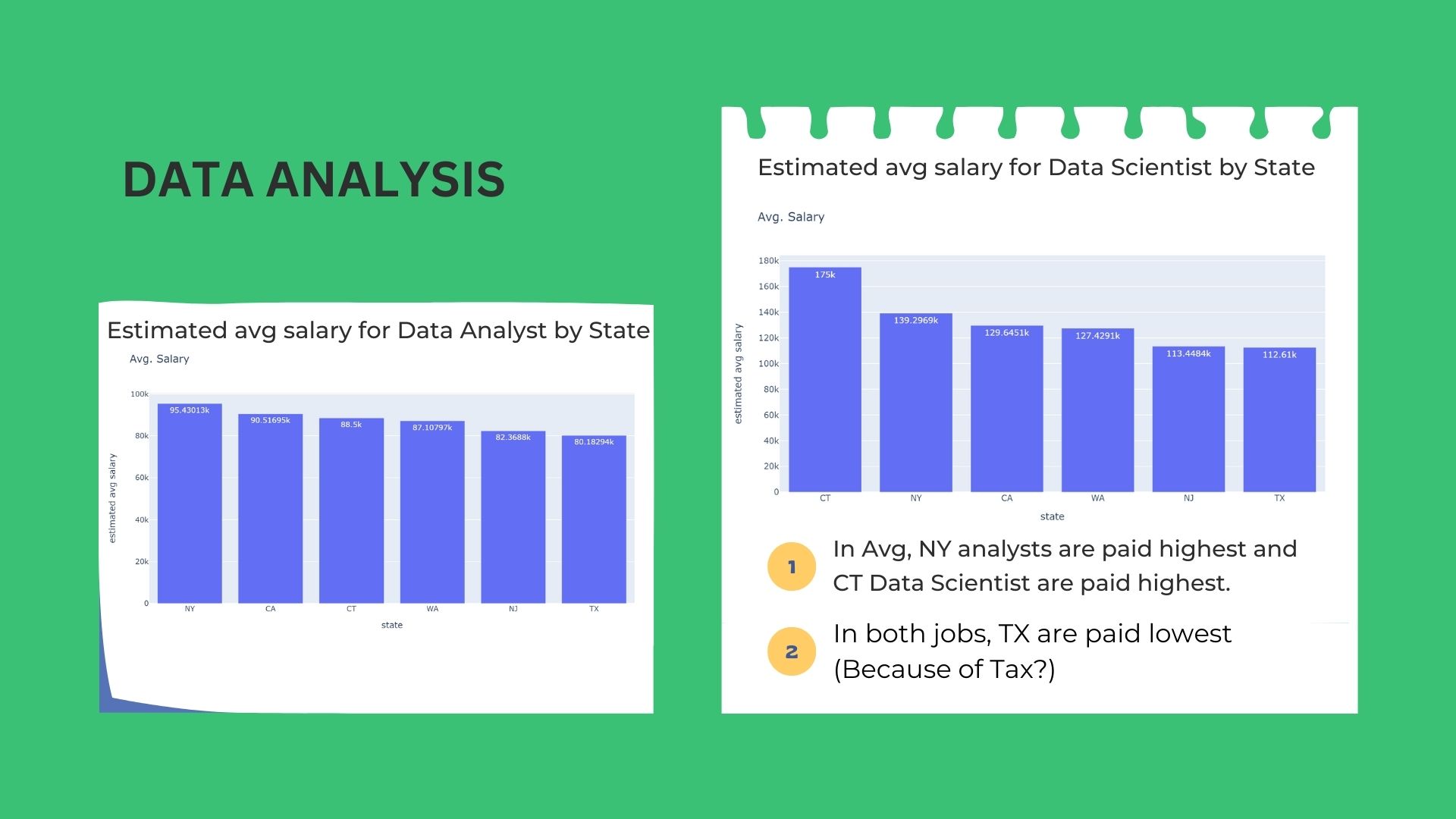
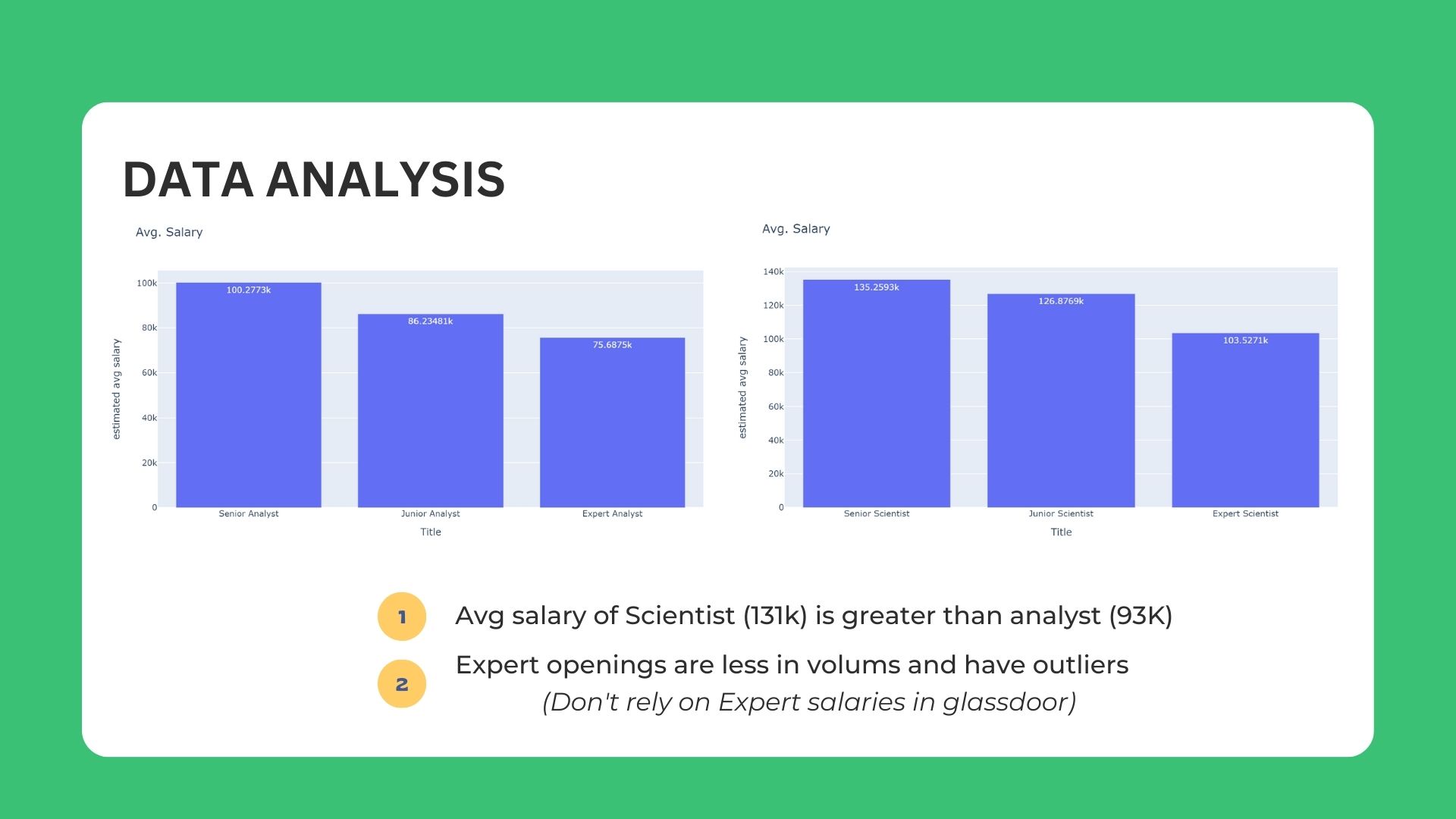
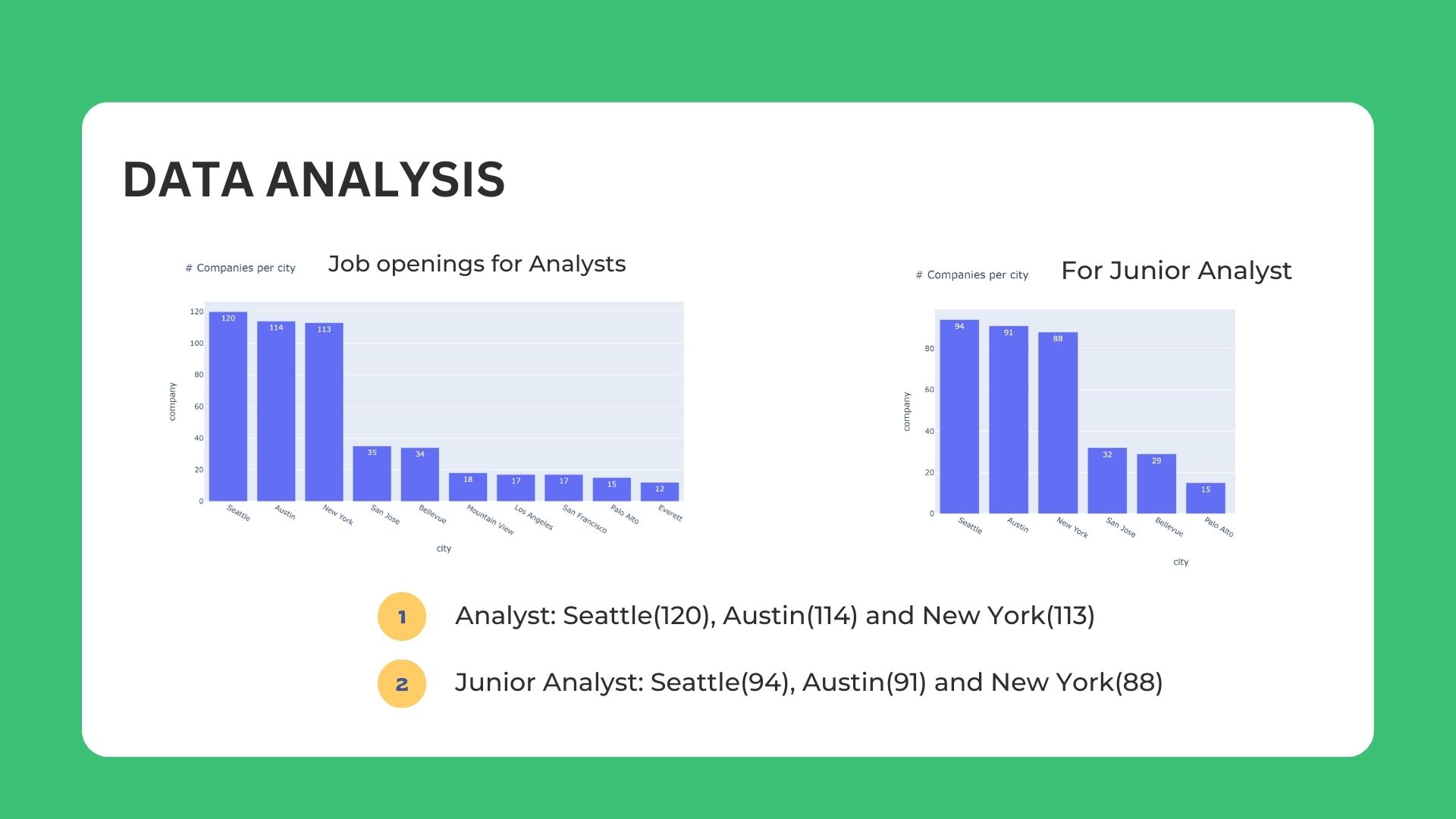
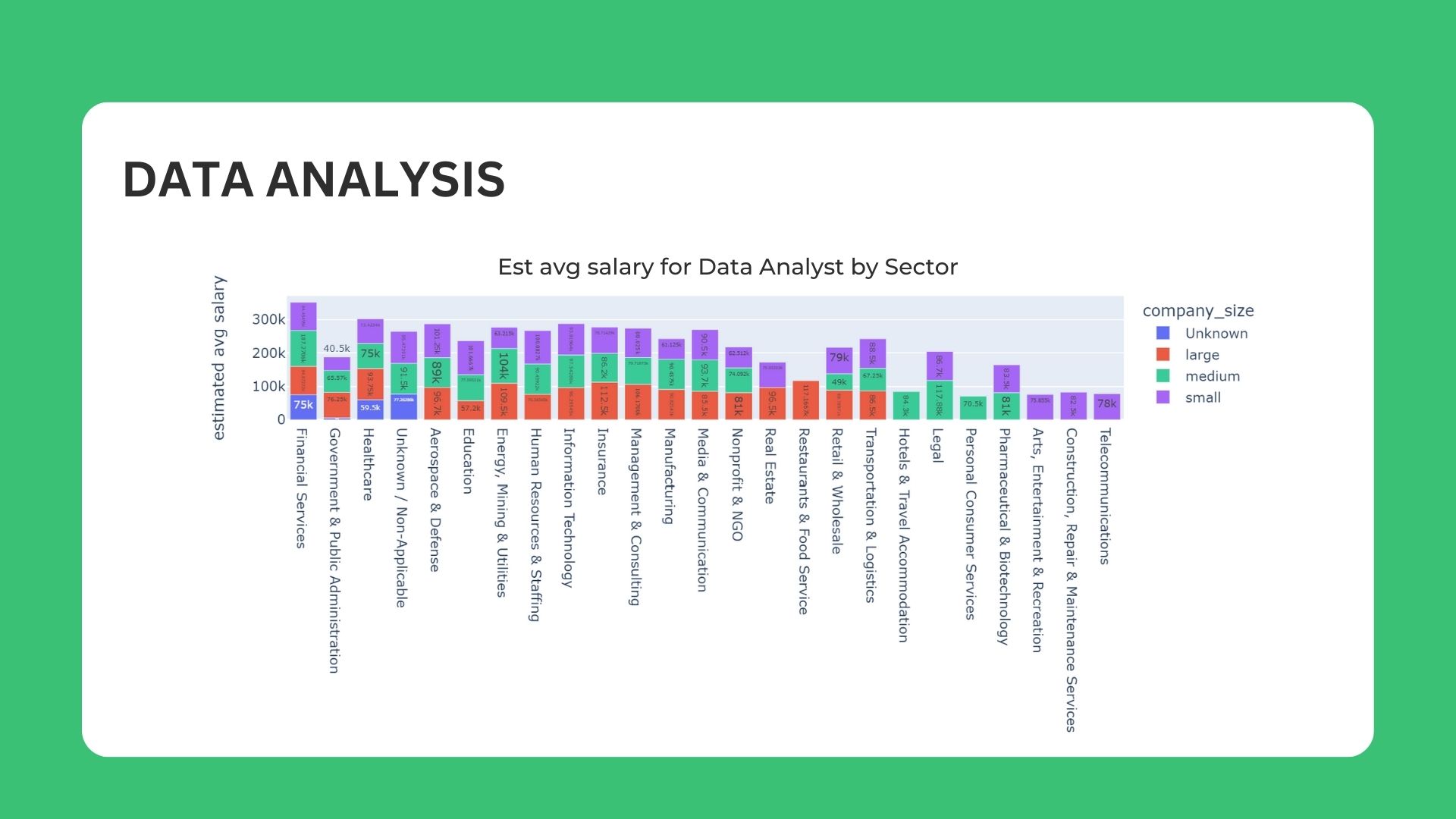
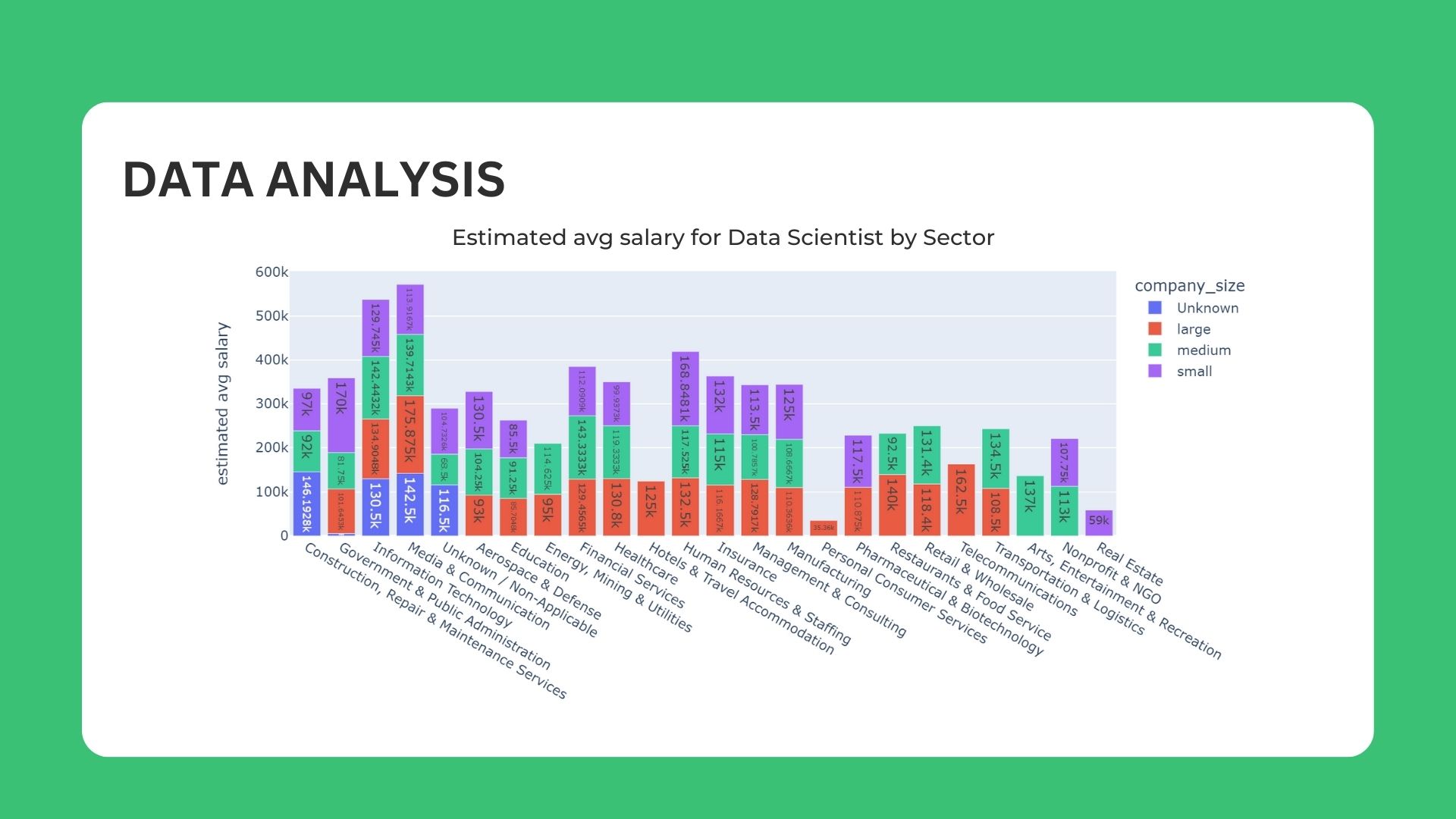
In-depth analysis using NLP for Job title & Skillset

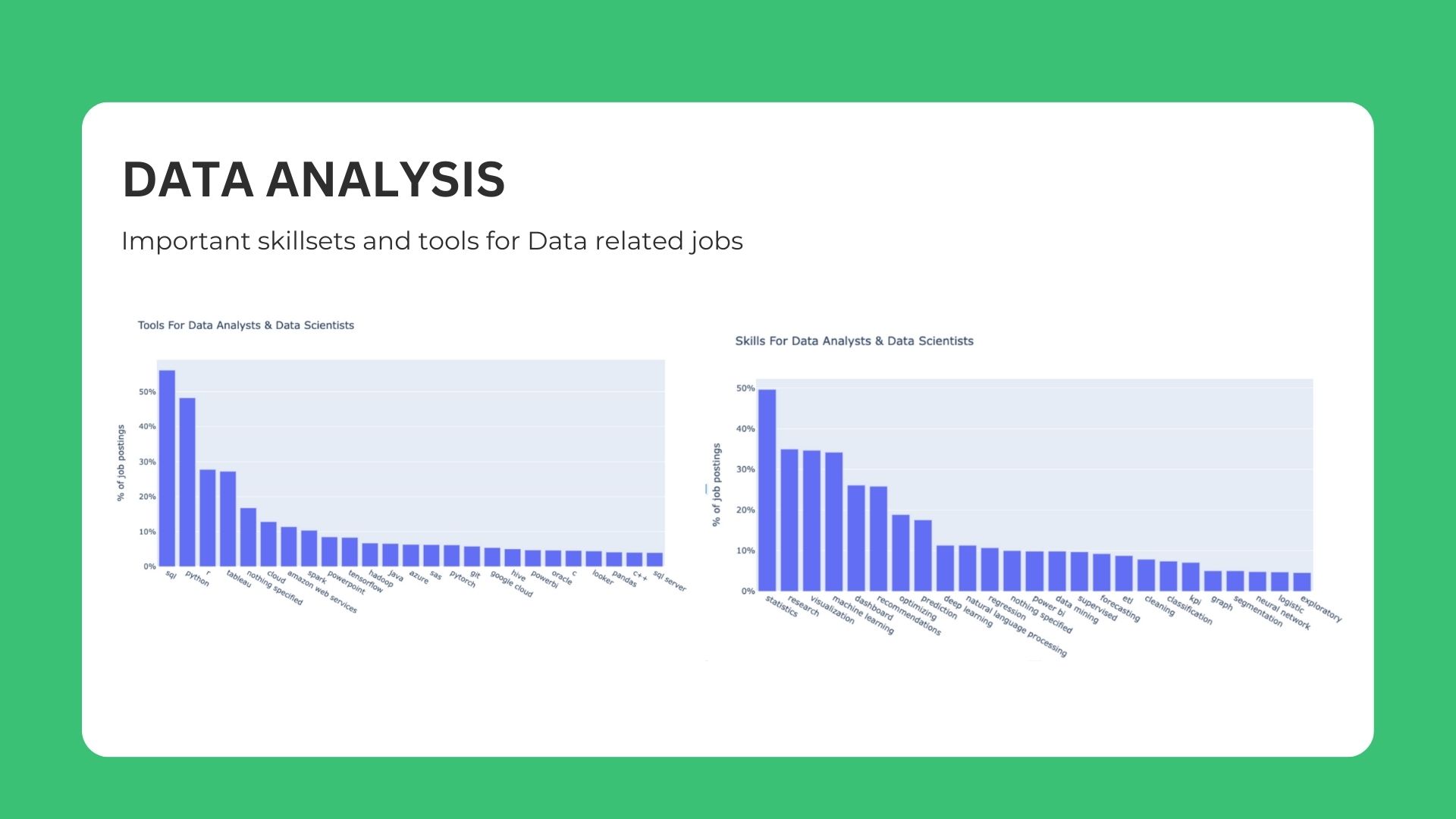
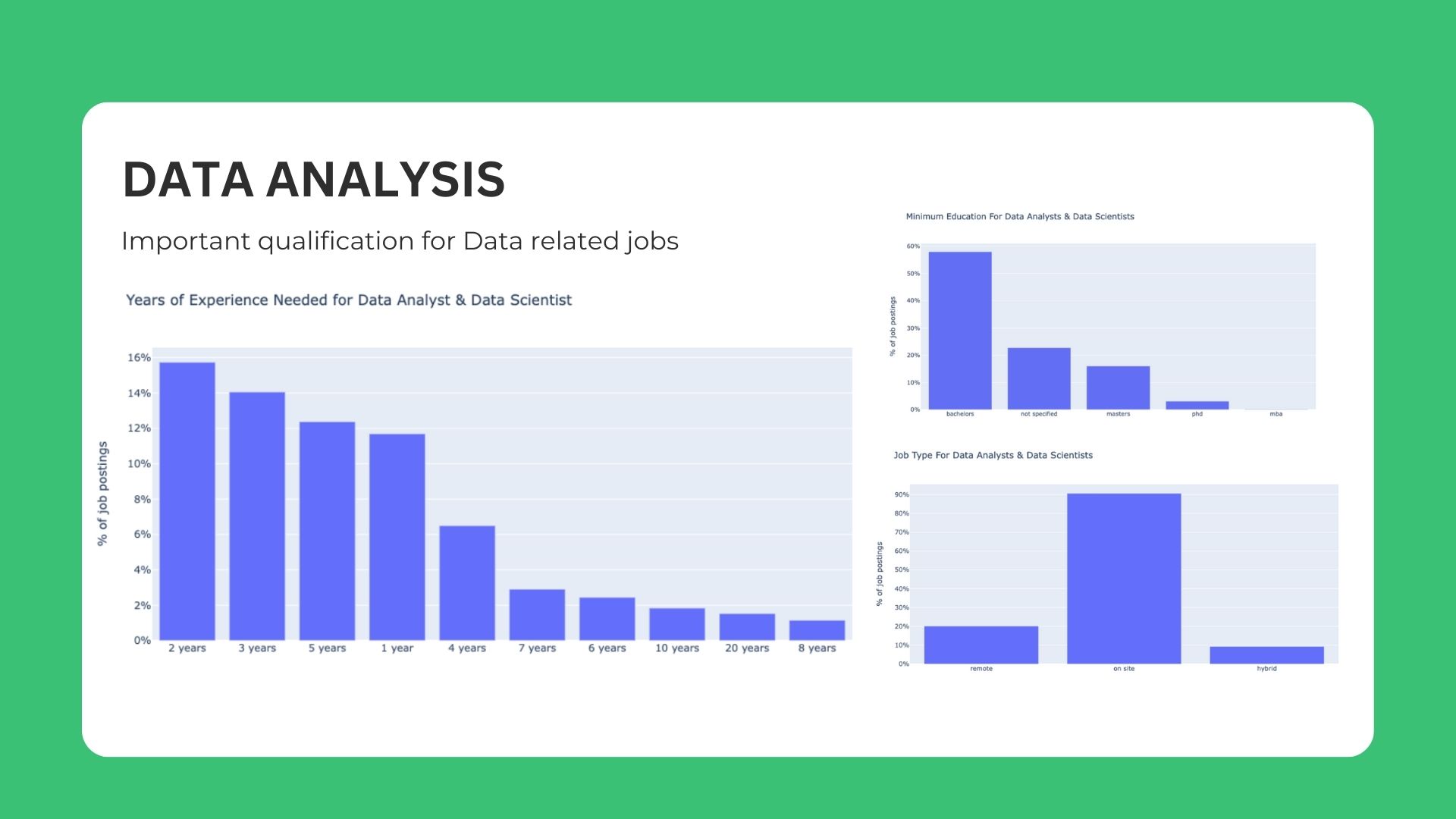
🚀 Key Insights