Breast cancer prediction

✅ About The Project
Breast cancer is one of the most common types of cancer affecting women worldwide. Early detection is critical in improving the chances of survival, and as such, there is a need for accurate and reliable tools for breast cancer prediction. In this data analysis project, we aim to build a model that can predict the likelihood of breast cancer based on patient data.
Using a dataset containing information on various attributes such as age, family history, and medical history, we will explore various machine learning algorithms such as KNN, Logistic Regression and decision tree to develop a model that can accurately predict the presence of breast cancer. Our analysis will include data preprocessing, feature selection, and model evaluation, with a focus on achieving high accuracy, precision, and recall.
Project overview
- Project Data & Process
- Exploratory Data Analysis
- KNN
- Logistic Regression
- Decision Tree
- Conclusion
📃 Project Data & Process
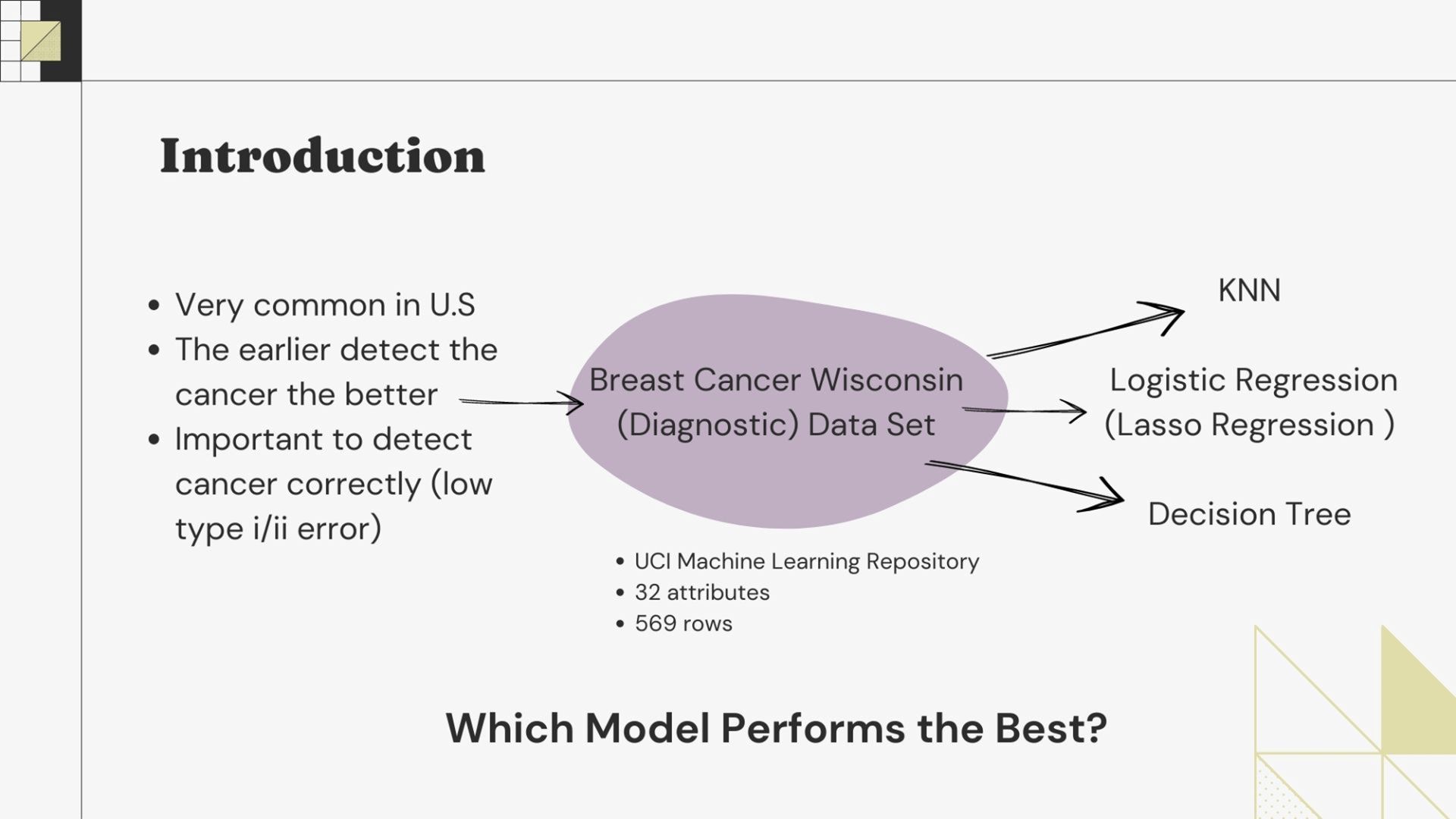
Breast Cancer Wisconsin (Diagnostic) Data Set provided by the UCI Machine Learning Repository to inspect if data analysis can provide valuable indication of this cancer. The dataset was already cleaned and contains 569 rows and 32 attributes.
90% of the data to train and validate our models. The remaining 10% will serve as the outside data the models have never seen before. Since our dataset is fairly small with only 569 observations, we separate the dataset this way to test the goodness of our models.

We will be taking following processes for each models:
- Feature Selection
- Resample the dataset
- Resample
- Confusion Matrix
- Train the model
- Test Model
🧐 Explatory Data Analysis
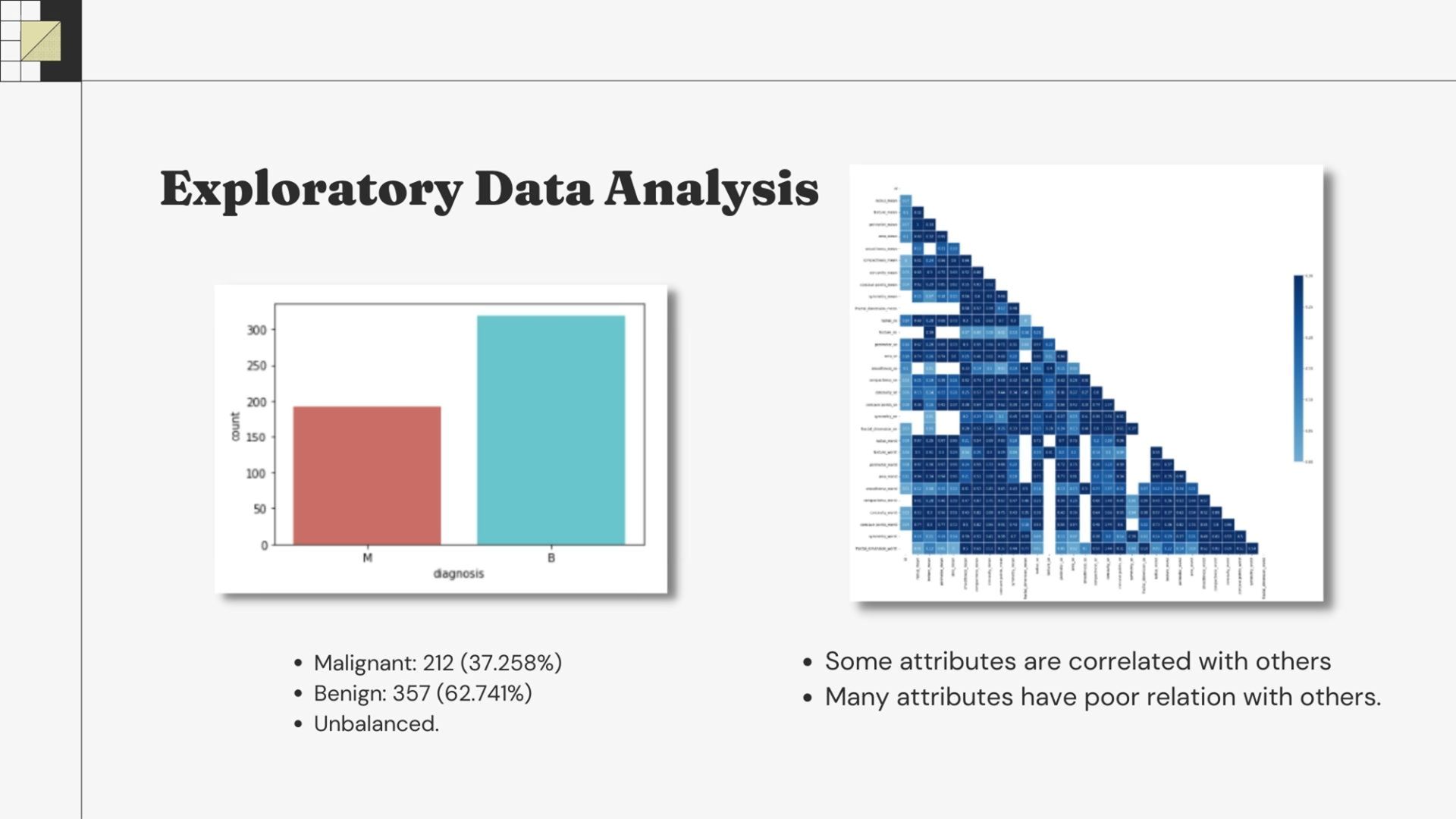
The total value of Malignant count is 212 which makes up 37.258% of the total diagnosis count and the Benign count is 357 which makes up 62.741% of the total diagnosis count.
The four correlations we found to be highly correlated are: radius_mean vs perimeter_mean, radius_mean vs area_mean, perimeter_mean vs area_mean, and radius_worst vs perimeter_worst.
K-Nearest Neighbor (KNN)
 • KNN is the most commonly used algorithm
for finding patterns in classification and regression problems
• KNN is the most commonly used algorithm
for finding patterns in classification and regression problems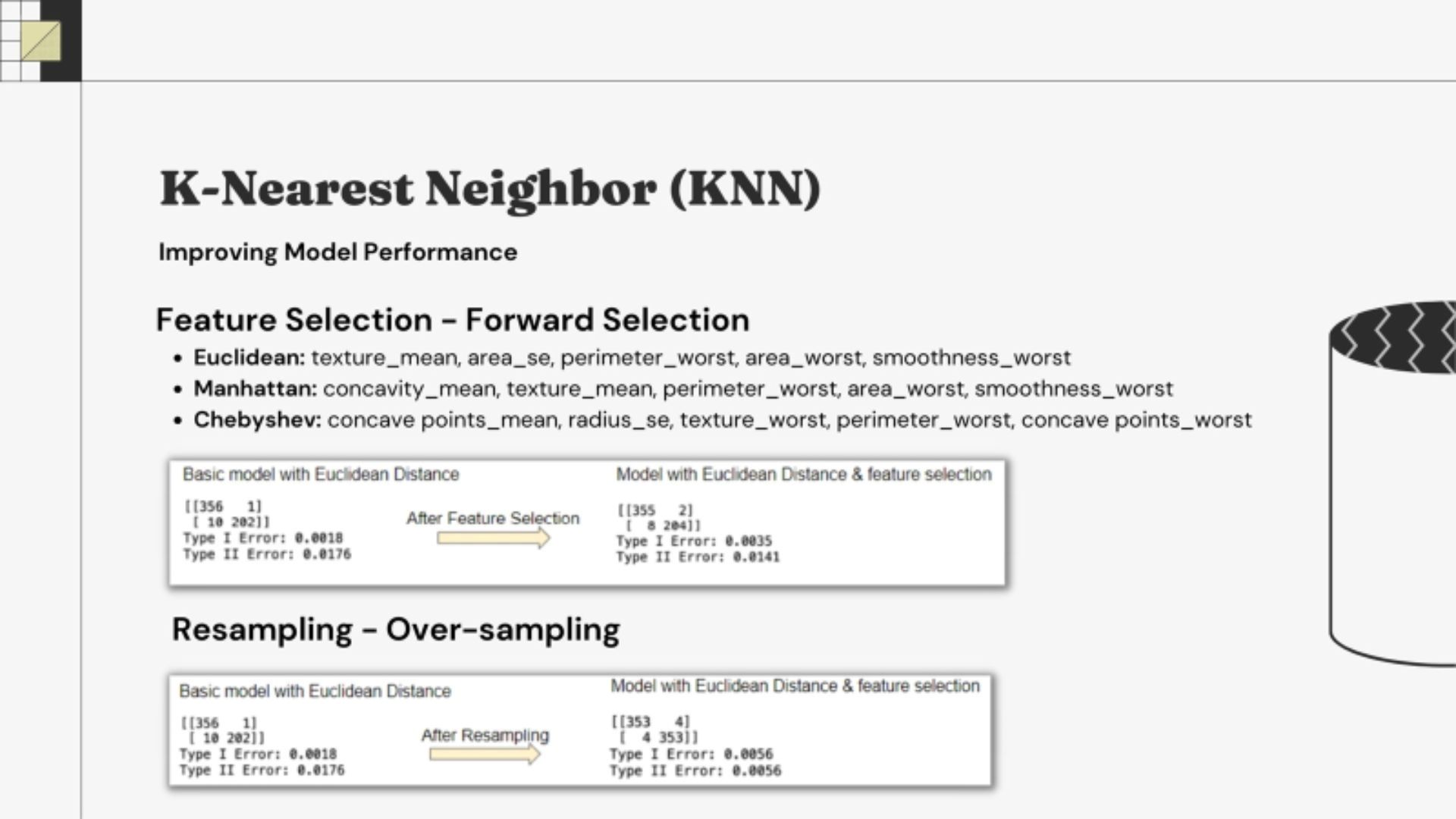 • Running Feature selection with three different distances & over sampling
• Running Feature selection with three different distances & over sampling  • Result of three different feature selection methods of KNN
• Result of three different feature selection methods of KNN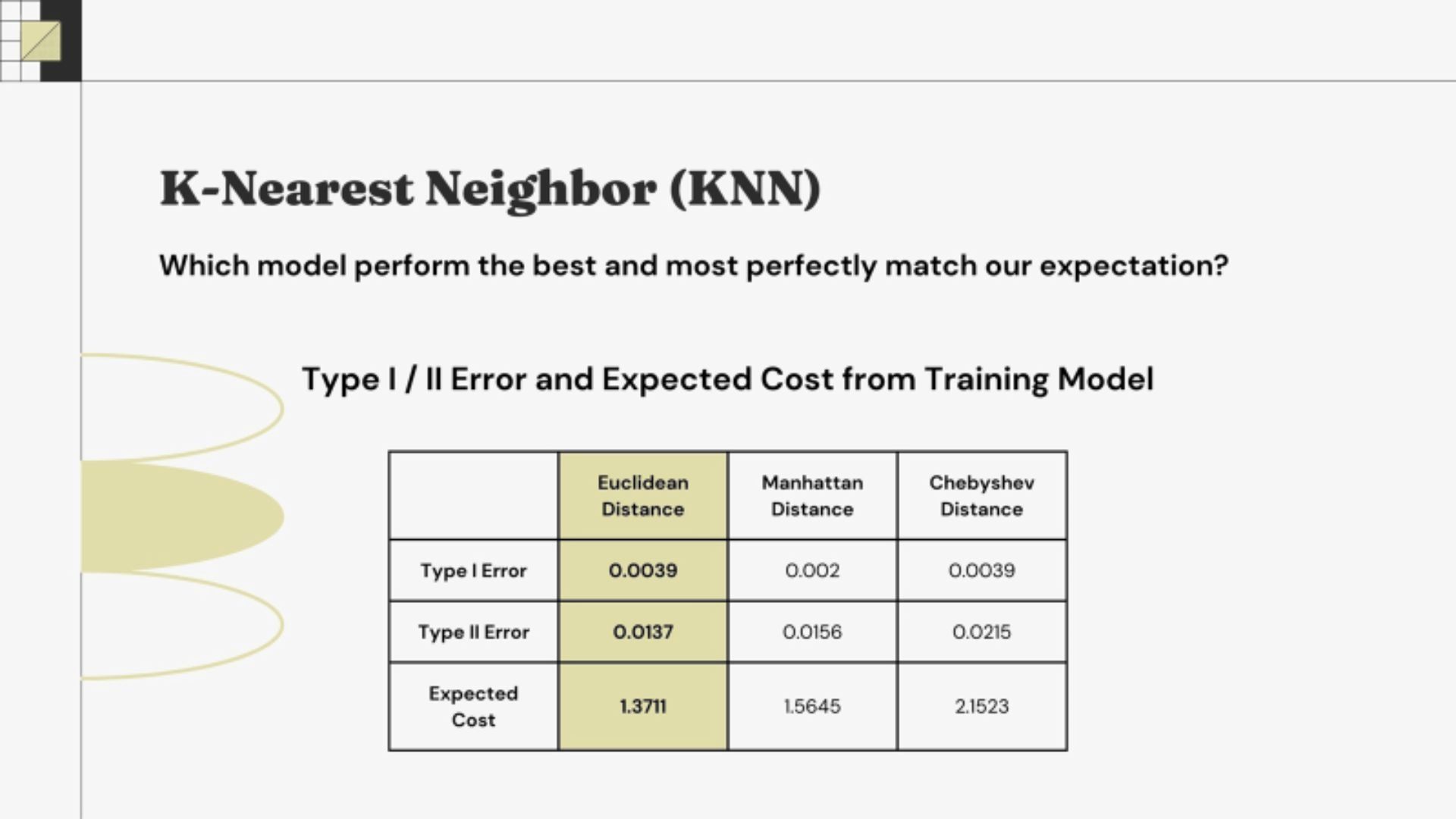 • Euclidean Distance showed lowest Type I and Type II Error
• Euclidean Distance showed lowest Type I and Type II ErrorLogistic Regression
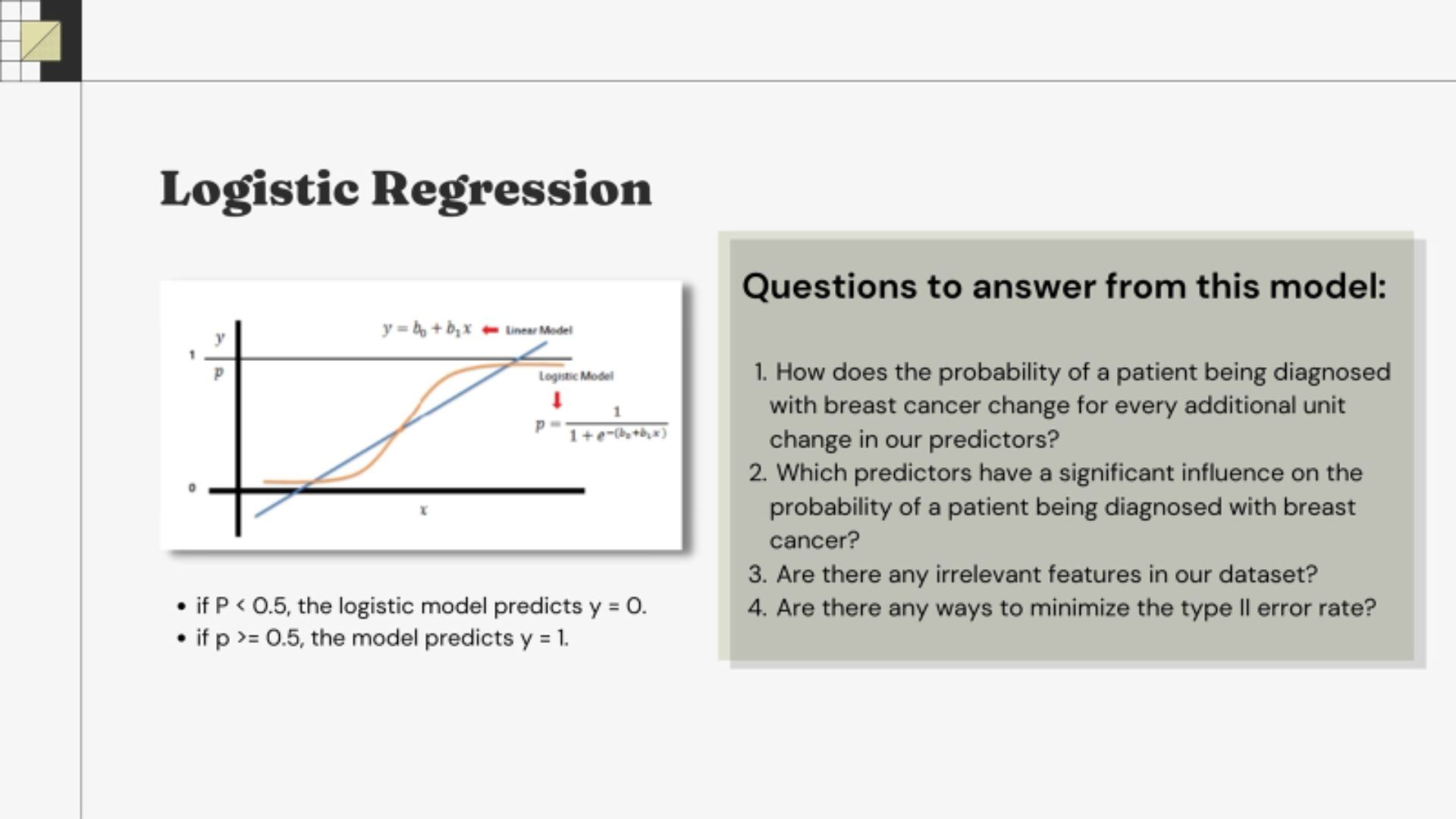 • Logistic regression is powerful methods to identify significant feature influence on the result
• Logistic regression is powerful methods to identify significant feature influence on the result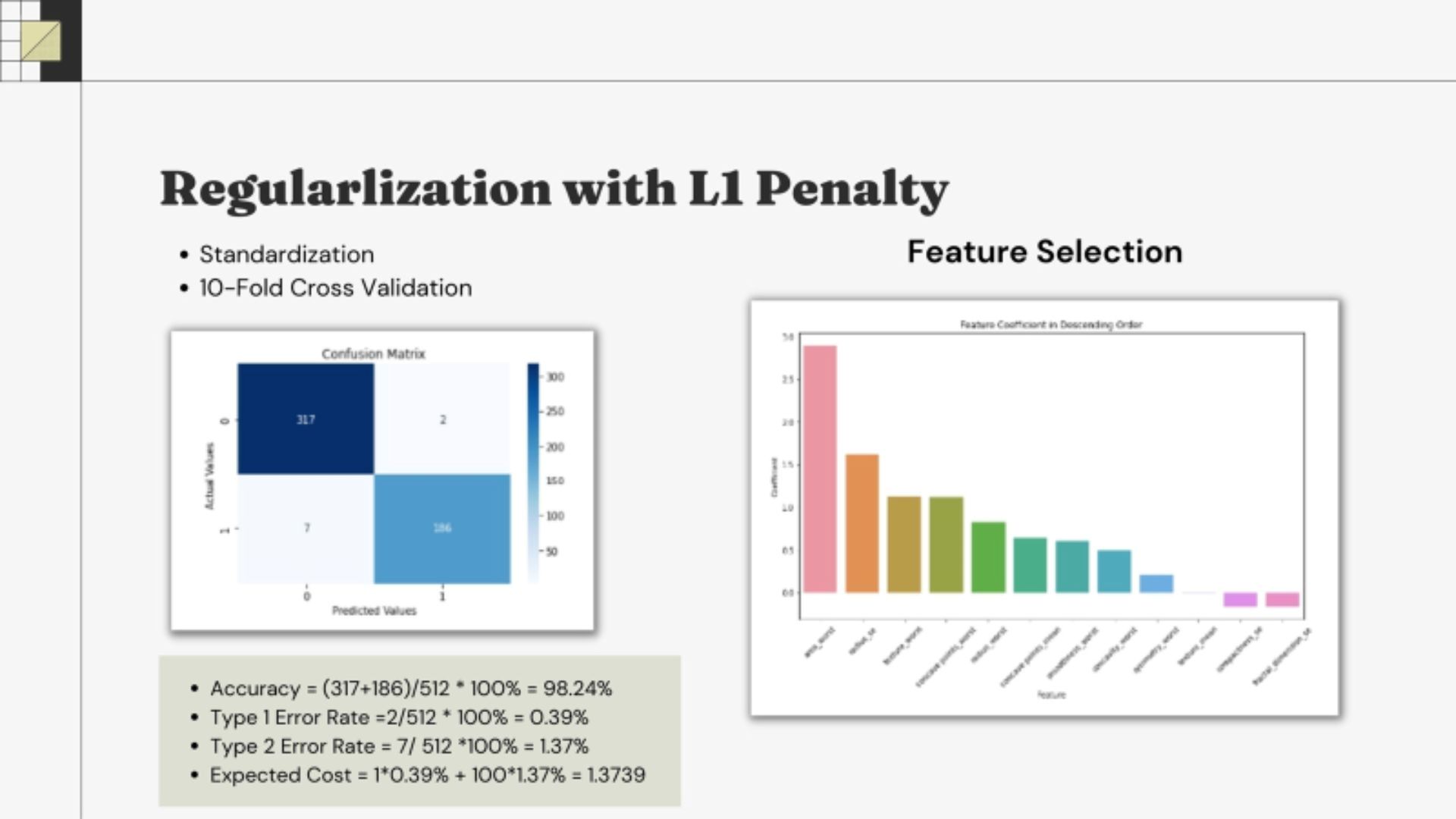 • Regularization with L1 Penalty to avoid overfitting issue
• Regularization with L1 Penalty to avoid overfitting issue 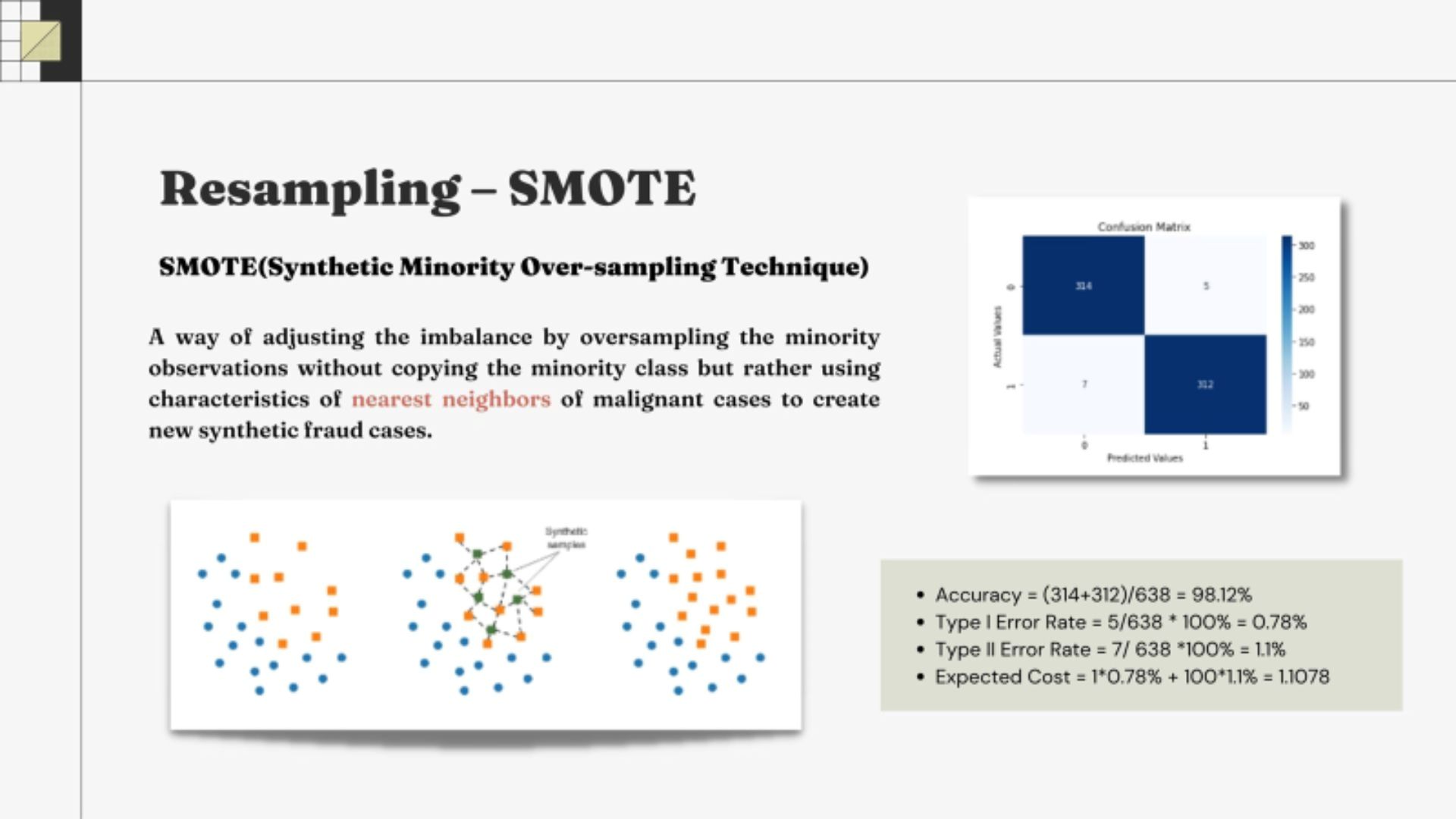 • SMOTE resampling adjust the imbalace of data by generating synthetic samples
• SMOTE resampling adjust the imbalace of data by generating synthetic samples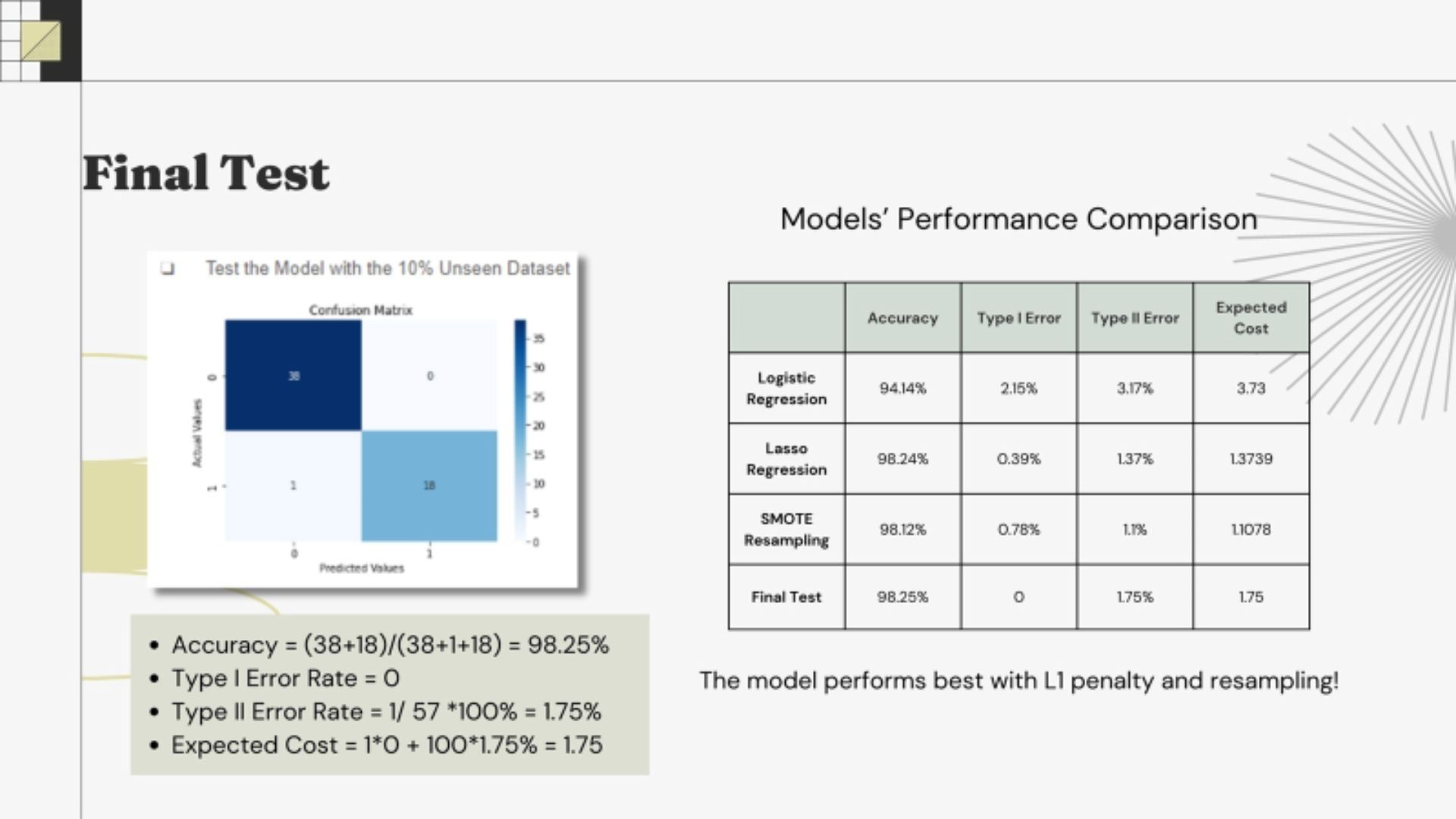 • The model performs best with the L1 Penalty and resampling
• The model performs best with the L1 Penalty and resamplingDecision Tree
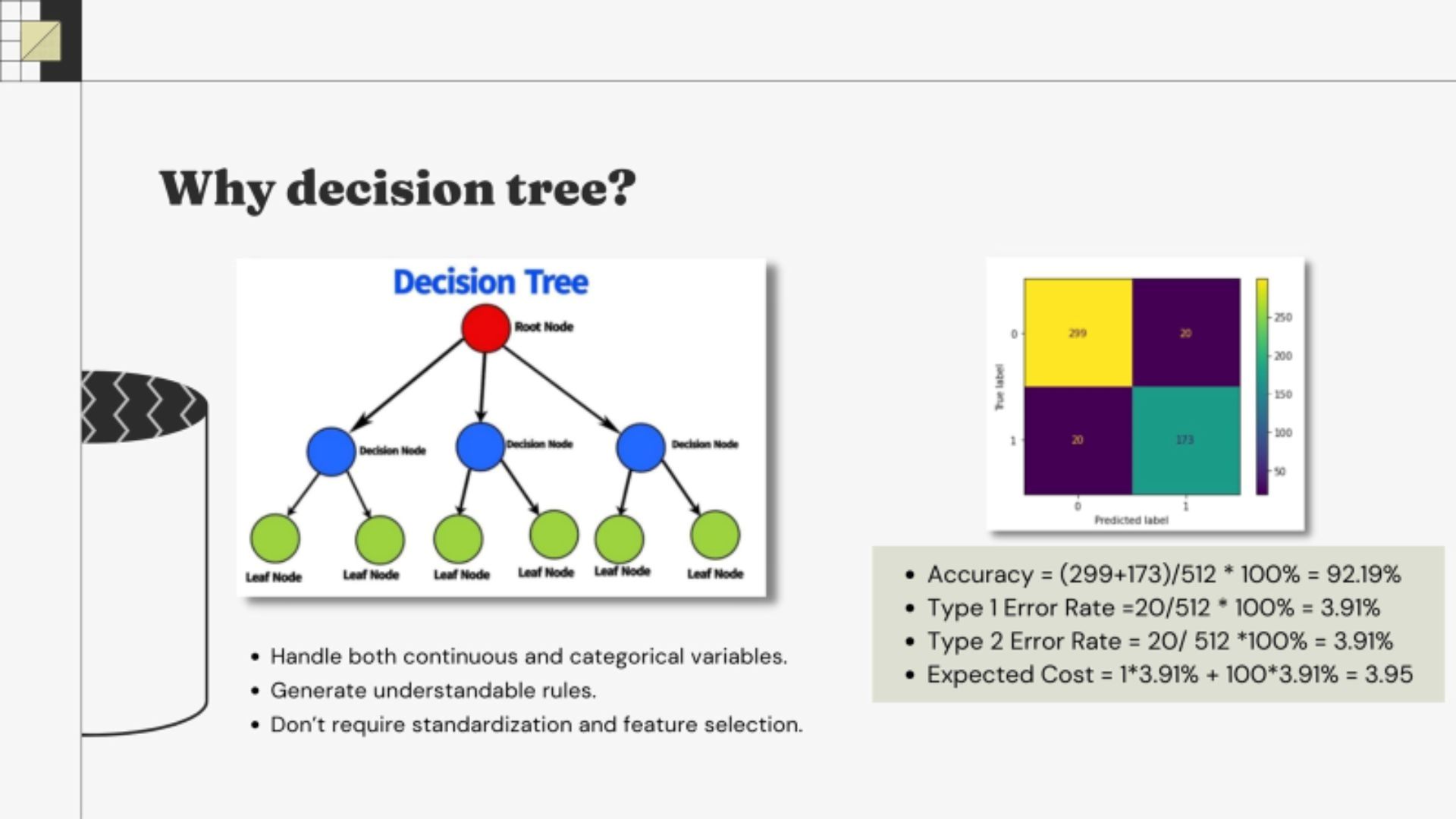 • Decision tree is handy method since it doesn't require standardization or feature selection
• Decision tree is handy method since it doesn't require standardization or feature selection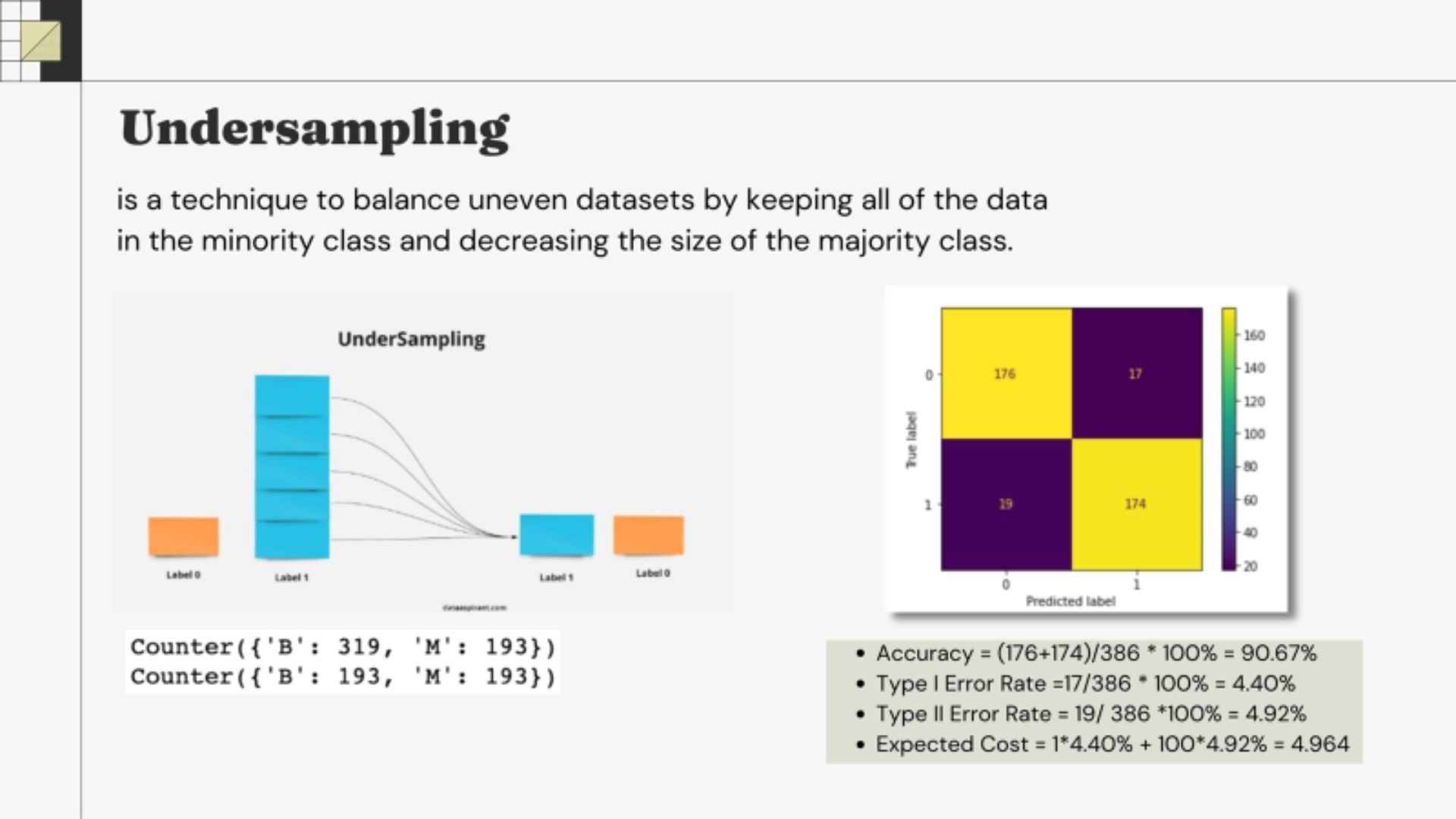 • Undersampling method to balance the dataset
• Undersampling method to balance the dataset  • Decision tree's max depths and features should be considered to avoid overfitting
• Decision tree's max depths and features should be considered to avoid overfitting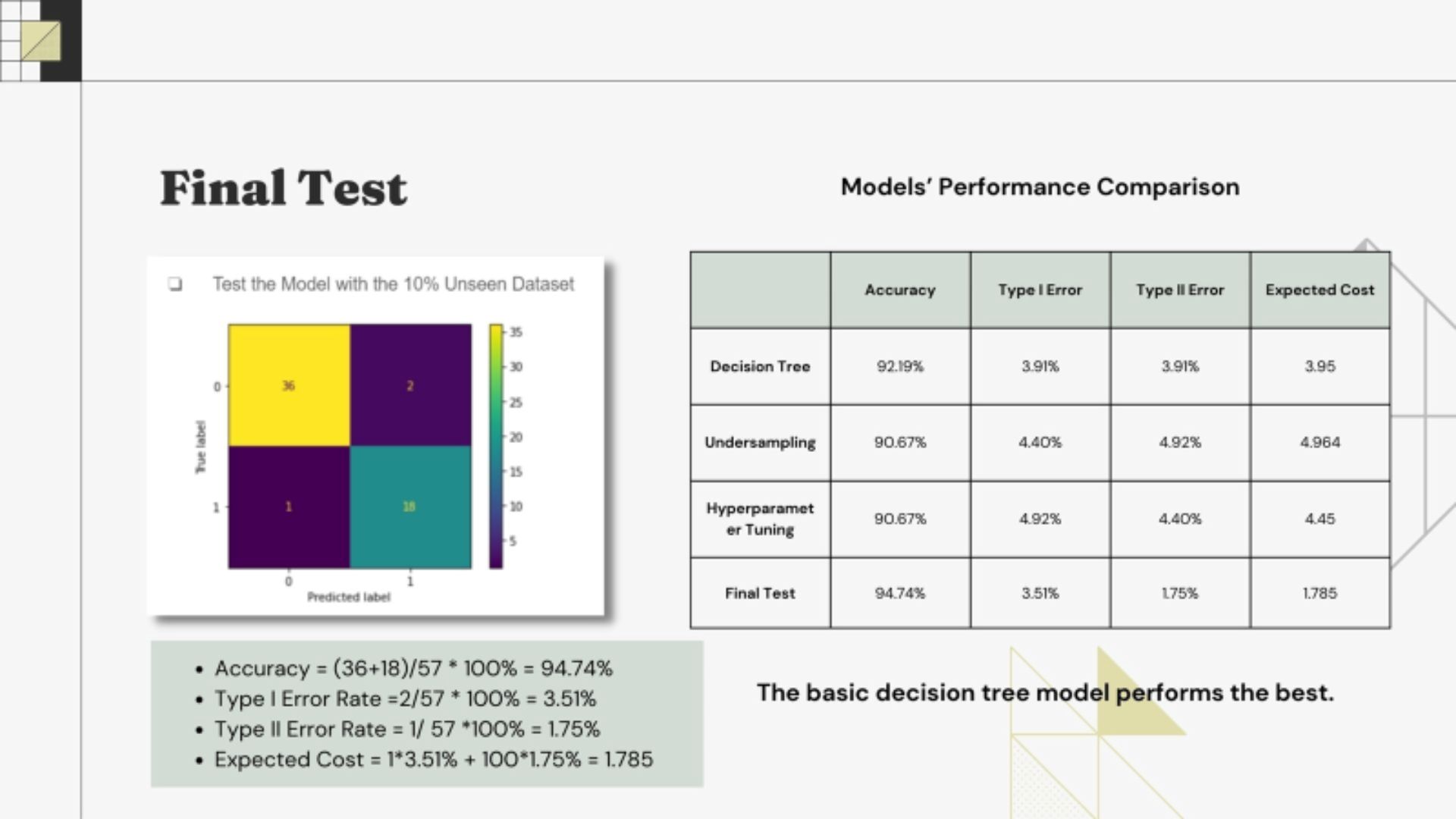 • Basic Desicion tree performed the best. This shows how powerfully automated tree models are
• Basic Desicion tree performed the best. This shows how powerfully automated tree models areConclusion
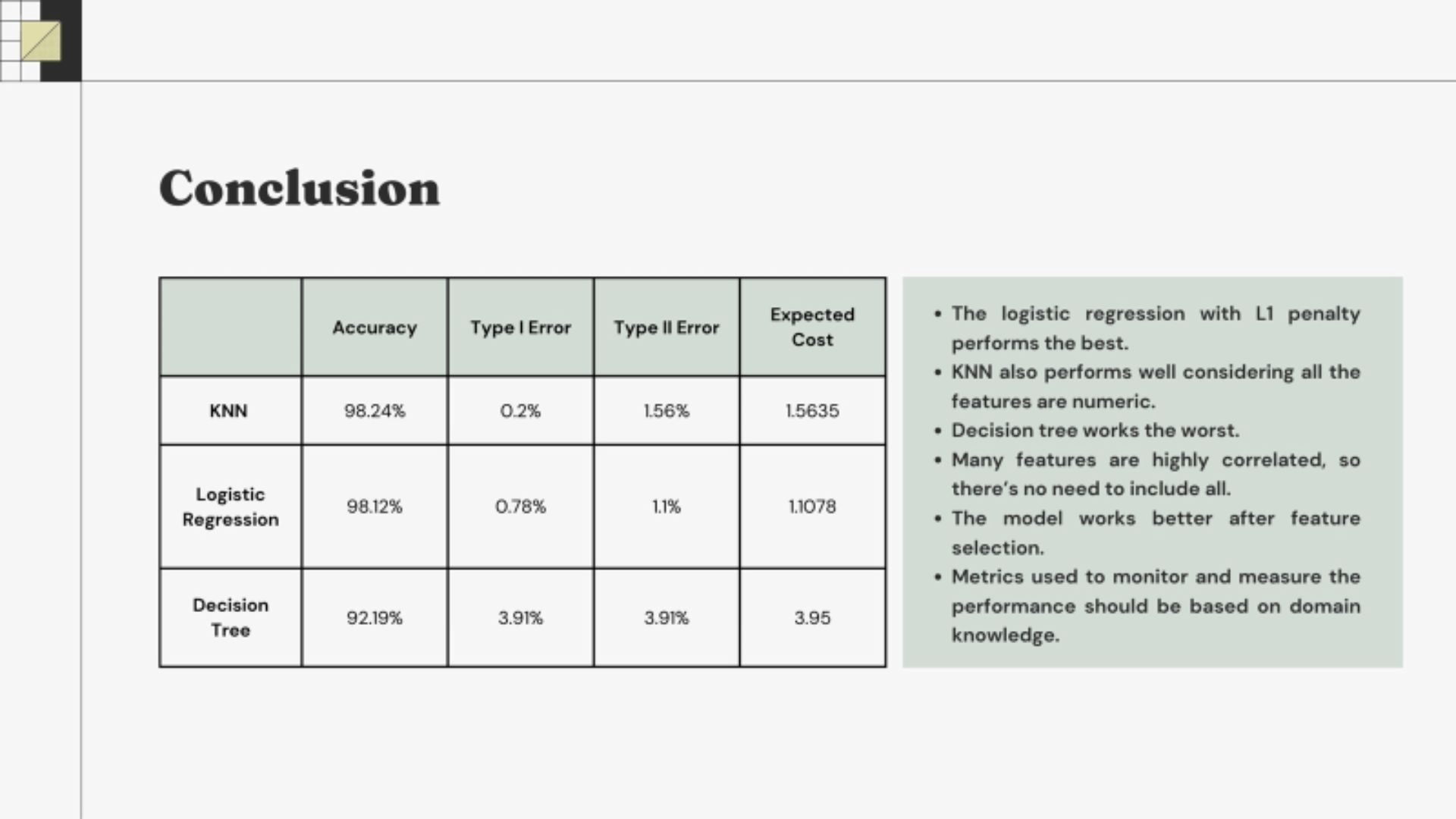
- Logistic regression with L1 penalty performed best
- Many features were highly correlated, therefore no need to include all the features
- Feature selection is an important steps to get a better perfoming modeling
- Domain knowledge is essential in calculating the expected cost, unique to the problem we try to solve